
「干货」编程语言十大经典算法,你知道几个?
|
算法与数据结构是计算机学习路上的内功心法,也是学好编程语言的重要基础。今天给大家介绍一下十大经典算法。
十大经典算法分别是:冒泡排序,插入排序,选择排序,希尔排序,快速排序,归并排序,桶排序,堆排序,计数排序,基数排序。
预备知识:算法稳定性 如果 a==b,排序前 a 在 b 的前面,排序后 a 在 b 的后面,只要会出现这种现象,我们则说这个算法不稳定(即使两个相等的数,在排序的过程中不断交换,有可能将后面的 b 交换到 a 的前面去)。
冒泡排序(Bubble Sort)是基于交换的排序,它重复走过需要排序的元素,依次比较相邻的两个元素的大小,保证最后一个数字一定是最大的,即它的顺序已经排好,下一轮只需要保证前面 n-1 个元素的顺序即可。
之所以称为冒泡,是因为最大/最小的数,每一次都往后面冒,就像是水里面的气泡一样。
排序的步骤如下:
例如,我们需要对数组 [98,90,34,56,21] 进行从小到大排序,每一次都需要将数组最大的移动到数组尾部。那么排序的过程如下动图所示:
前面说的冒泡排序是每一轮比较确定最后一个元素,中间过程不断地交换。而选择排序就是每次选择剩下的元素中最小的那个元素,直到选择完成。
排序的步骤如下:
比如,现在我们需要对 [98,90,34,56,21] 进行排序,动态排序过程如下:
 选择排序是每次选择出最小的放到已经排好的数组后面,而插入排序是依次选择一个元素,插入到前面已经排好序的数组中间,当然,这是需要已经排好的顺序数组不断移动。步骤描述如下:
以数组 [98,90,34,56,21] 为例,动态排序过程如下:
 希尔排序(Shell’s Sort)又称“缩小增量排序”(Diminishing Increment Sort),是插入排序的一种更高效的改进版本,同时该算法是首次冲破 O(n^2*n*2) 的算法之一。
插入排序的痛点在于不管是否是大部分有序,都会对元素进行比较,如果最小数在数组末尾,想要把它移动到数组的头部是比较费劲的。希尔排序是在数组中采用跳跃式分组,按照某个增量 gap 进行分组,分为若干组,每一组分别进行插入排序。再逐步将增量 gap 缩小,再每一组进行插入排序,循环这个过程,直到增量为 1。
希尔排序基本步骤如下:
以数组 [98,90,34,56,21,11,43,61] 为例子,排序的动图如下:
 快速排序比较有趣,选择数组的一个数作为基准数,一趟排序,将数组分割成为两部分,一部分均小于/等于基准数,另外一部分大于/等于基准数。然后分别对基准数的左右两部分继续排序,直到序列有序。这体现了分而治之的思想,其中还应用到挖坑填数的策略。
算法的步骤如下:
以数组 [61,90,34,56,21,11,43,68] 为例,动态排序过程如下:
 前面学的快速排序,体现了分治的思想,但是不够典型,而归并排序则是非常典型的分治策略。归并的总体思想是先将数组分割,再分割…分割到一个元素,然后再两两归并排序,做到局部有序,不断地归并,直到数组又被全部合起来。
排序步骤大致如下:
以数组 [61,90,34,56,21,11,43,68] 为例,每一次都是对数组分成两半,直至不能拆分,再两两合并,合并的时候相当于对有序的两个子数组合并。
动态执行过程如下:
 计数排序,不是基于比较,而是基于计数。
计数排序步骤如下:
假设有几个青少年,他们年龄很接近,分别是 11、9、11、 13、12、14、15、13,现在需要给他们按照年龄排序。首先先遍历一遍,找出最小的 min 和最大的元素 max,创建一个大小为 max – min + 1 的数组,再遍历一次,统计数字个数,写到数组中。
然后再遍历一次统计数组,将每个元素置为前面一个元素加上自身,为什么这样做呢?
为了让统计数组存储的元素值等于相应整数的最终排序位置,这样我们就可以做到稳定排序,比如下面的 15 对应的是 8,也就是 15 在数组中出现的是第 8 个元素,从后面开始遍历,我们就可以保持稳定性。
比如原数组从后往前遍历到 13 的时候, 13 对应的位置是 6,那么此时从后往前遍历到的第一个 13 就是在第 6 个元素位置。后面再遇到 13,就放到第 5 个元素位置,不会打乱它们的相对位置。
动态过程如下:
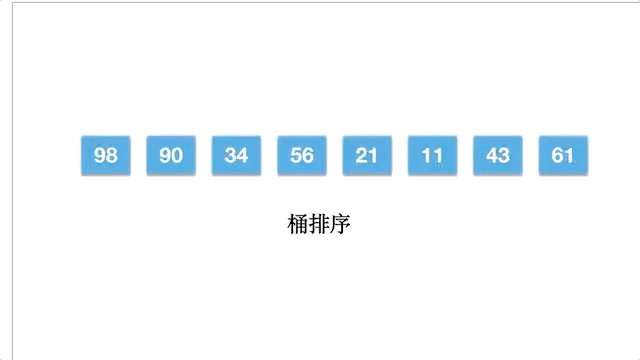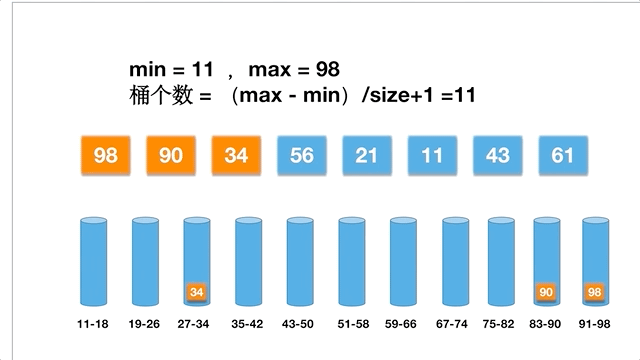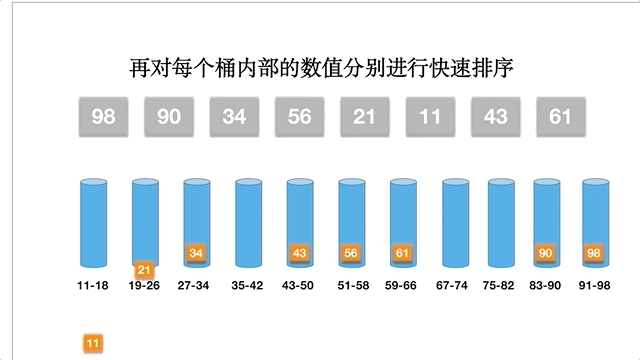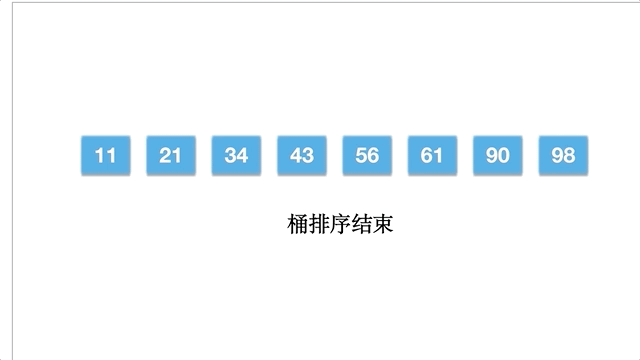
 桶排序,是指用多个桶存储元素,每个桶有一个存储范围,先将元素按照范围放到各个桶中,每个桶中是一个子数组,然后再对每个子数组进行排序,最后合并子数组,成为最终有序的数组。这其实和计数排序很相似,只不过计数排序每个桶只有一个元素,而且桶的值为元素的个数。
桶排序的具体步骤:
以数组 [98,90,34,56,21,11,43,61] 为例,桶排序的动态过程:
 堆排序,就是利用大顶堆或者小顶堆来设计的排序算法,是一种选择排序。堆是一种完全二叉树:
我们一般使用数组来对堆结构进行存储,下面我们只说大顶堆(元素按照从小到大排序),假设数组为 nums[],则第 i 个数满足:num >= nums[2i+1] 且 num >= nums[2i+2],第 i 个数在堆上的左节点就是数组中下标索引 2i+1 的元素,其右节点就是数组中下标索引 2i+2 的元素。
排序的思路为:
倘若一个数组为 [11,21,34,43,56,61,90,98],动态的过程如下:
 基数排序比较特殊,特殊在它只能用在整数(自然数)排序,而且不是基于比较的,其原理是将整数按照位分成不同的数字,按照每个数各位值逐步排序。何为高位,比如 81,1 就是低位, 8 就是高位。 分为高位优先和低位优先,先比较高位就是高位优先,先比较低位就是低位优先。下面我们讲高位优先。
主要的步骤如下:
以数组 [98,90,34,56,21,11,43,61,39] 为例,动态的排序过程如下:
 十个算法的复杂度以及特点总结一下:
每一种排序,都有其优缺点,我们应该根据场景选择合适的排序算法。
 扫码关注微信公众号,了解更多算法内容。
|


下载说明:
1.本站资源都是白菜价出售,同样的东西,我们不卖几百,也不卖几十,甚至才卖几块钱,一个永久会员能下载全站100%源码了,所以单独购买也好,会员也好均不提供相关技术服务。
2.如果源码下载地址失效请联系站长QQ进行补发。
3.本站所有资源仅用于学习及研究使用,请必须在24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担。资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您权益请联系本站删除!
4.本站站内提供的所有可下载资源(软件等等)本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发);但本网站不能保证资源的准确性、安全性和完整性,由于源码具有复制性,一经售出,概不退换。用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug;同时本站用户必须明白,【安安资源网】对提供下载的软件等不拥有任何权利(本站原创和特约原创作者除外),其版权归该资源的合法拥有者所有。
5.请您认真阅读上述内容,购买即以为着您同意上述内容,由于源码具有复制性,一经售出,概不退换。
安安资源网 » 「干货」编程语言十大经典算法,你知道几个?
1.本站资源都是白菜价出售,同样的东西,我们不卖几百,也不卖几十,甚至才卖几块钱,一个永久会员能下载全站100%源码了,所以单独购买也好,会员也好均不提供相关技术服务。
2.如果源码下载地址失效请联系站长QQ进行补发。
3.本站所有资源仅用于学习及研究使用,请必须在24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担。资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您权益请联系本站删除!
4.本站站内提供的所有可下载资源(软件等等)本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发);但本网站不能保证资源的准确性、安全性和完整性,由于源码具有复制性,一经售出,概不退换。用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug;同时本站用户必须明白,【安安资源网】对提供下载的软件等不拥有任何权利(本站原创和特约原创作者除外),其版权归该资源的合法拥有者所有。
5.请您认真阅读上述内容,购买即以为着您同意上述内容,由于源码具有复制性,一经售出,概不退换。
安安资源网 » 「干货」编程语言十大经典算法,你知道几个?


